栏目分类
你的位置:Kaiyun (中国)智能科技股份有限公司官网 > 新闻资讯 >

密集模子的推理才略也能和 DeepSeek-R1 掰手腕了?开云体育
华为哄骗纯昇腾集群覆按出的盘古 Ultra,在数学竞赛、编程等推理任务当中,和 R1 打得有来有回。
要道是模子参数目只须 135B,通盘覆按过程零英伟达含量,而且莫得出现蚀本尖峰。
通过编削的模子架构和系统优化战略,盘古 Ultra 领有优异的性能发扬和 52% 以上的算力哄骗率。
况兼有网友默示,覆按过程中莫得出现蚀本尖峰这一特征,似乎此前从未终了。

135B 密集模子并排 DeepSeek-R1
算作一个参数目 135B 密集模子,盘古 Ultra 达到了同模范密集模子的最优发扬,致使不错与 DeepSeek-R1 等参数目更大的 MoE 模子竞争。
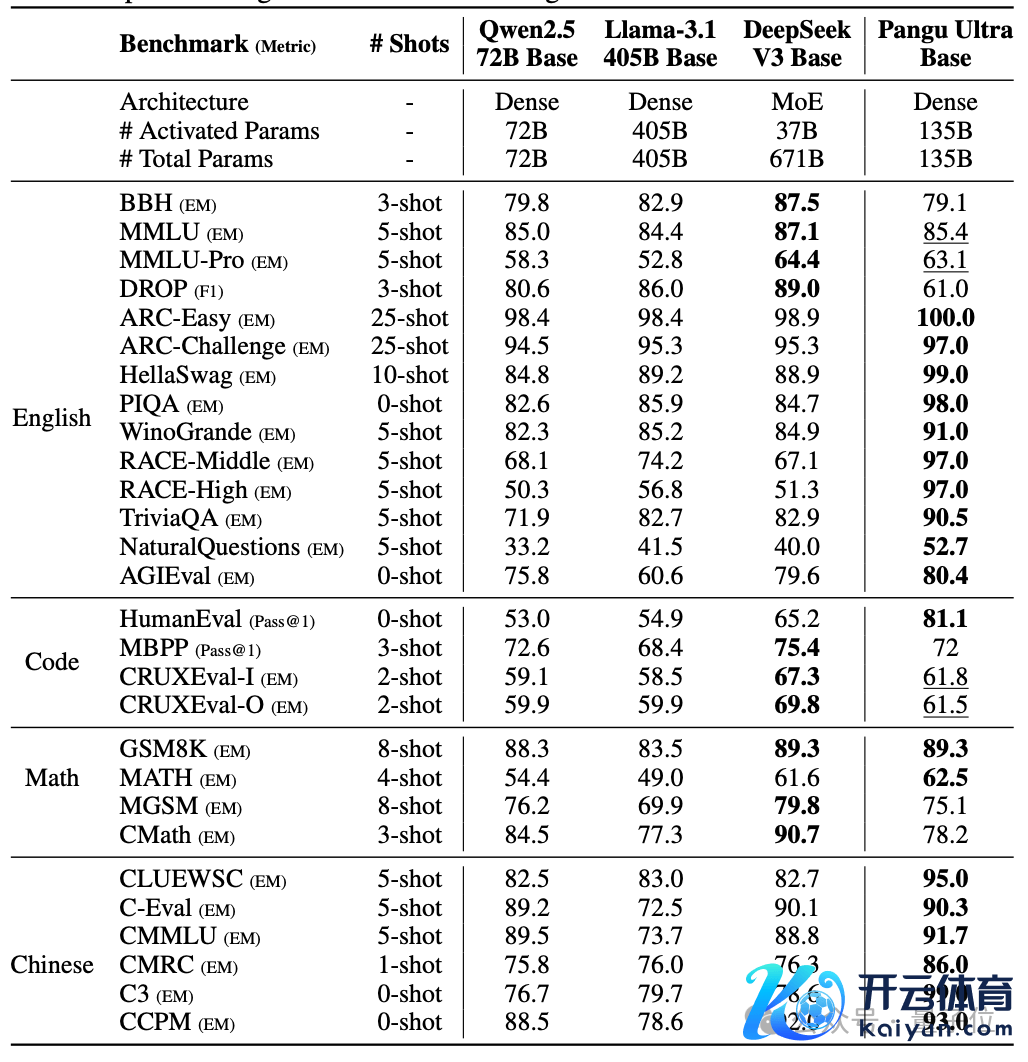
在预覆按阶段模子的评测中,盘古 Ultra 在绝大部分英文基准任务和一齐华文任务上得到了最好性能,优于 Llama 405B、DeepSeek-V3 等 baseline 模子。
尤其在 MMLU、TriviaQA、GSM8K 等具有挑战性的数据集上,盘古 Ultra 展现出了超卓的说话泄露和推理才略。
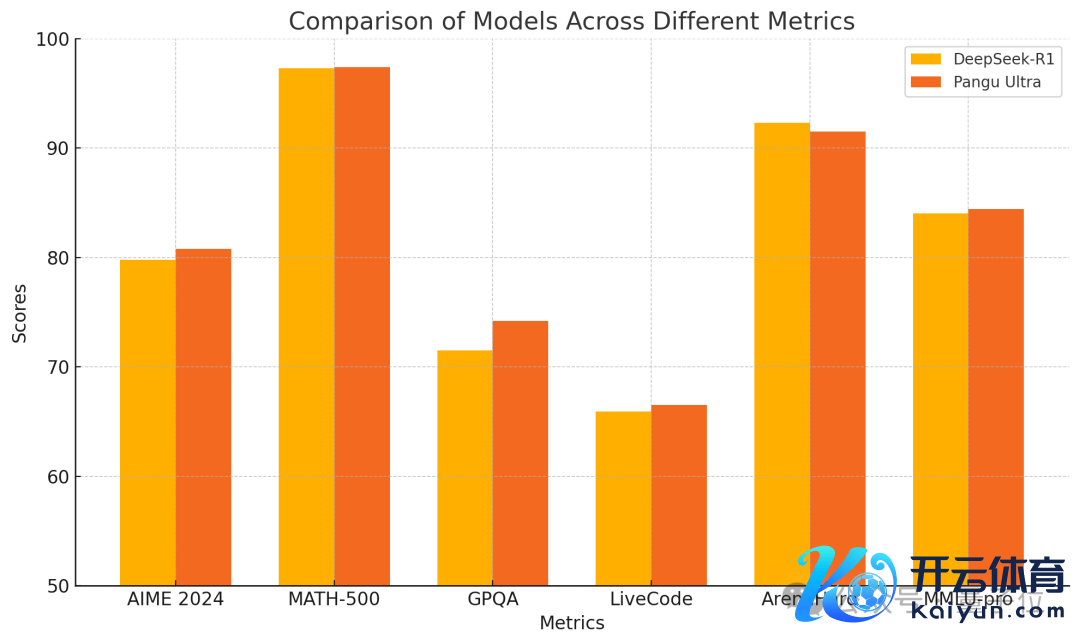
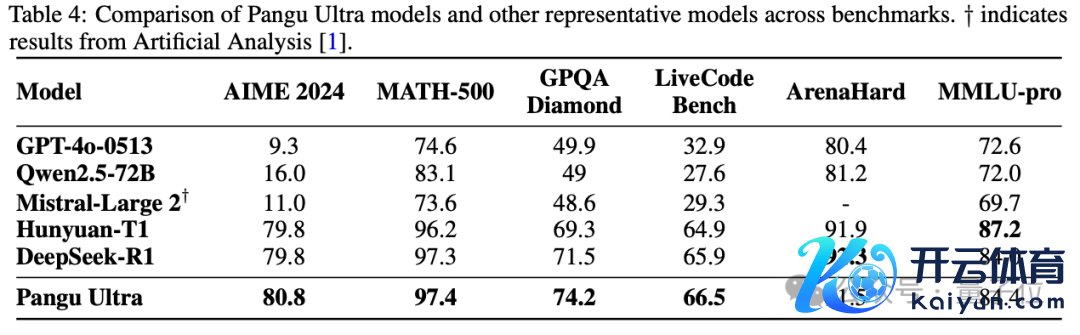
经过教唆调优后,盘古 Ultra 的性能进一步耕种,尤其在 AIME 2024、MATH-500 等数学推理任务和 LiveCodeBench 等编程竞赛题上达到了 SOTA 水平。
概述来看,盘古 Ultra 特出了包括 GPT-4o、Mistral-Large 2 等纷乱模子,与 DeepSeek-R1 等 MoE 模子竞争蛮横。
同期,盘古 Ultra 在 Arena Hard、MMLU-pro 等涵盖通用说话泄露和推理的评测中也发扬优异。
那么,为了终了这么的恶果,盘古 Ultra 采纳了哪些要道技艺呢?
“三明治”层归一化架构
如前文所述,盘古 Ultra 是一款 135B 参数目的密集模子,使用了 94 层的网罗结构。
盘古 Ultra 采纳了分组查询细心力(GQA)机制,包含 96 个查询头(query head)和 8 个键值头(key-value head)。
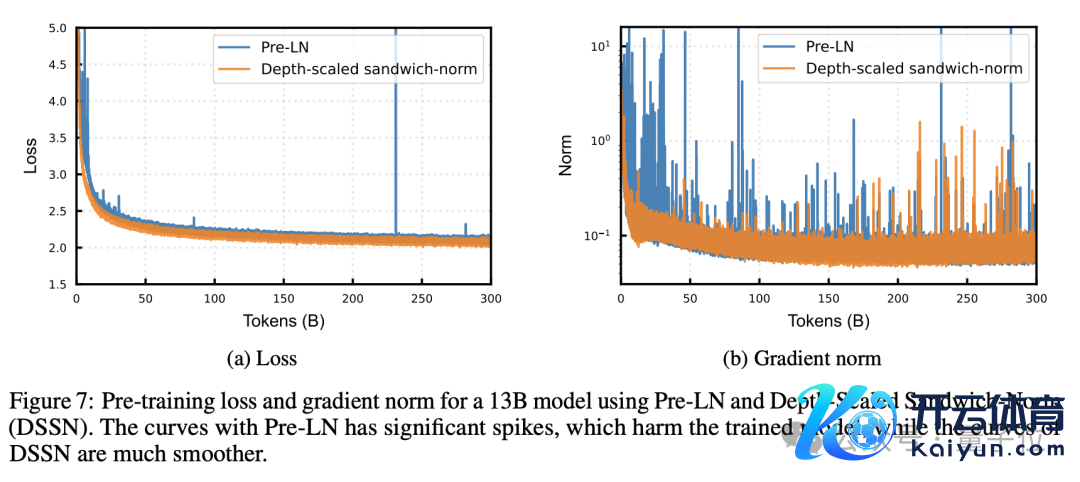
为了料理覆按超深网罗濒临的不褂讪性和敛迹艰难等问题,盘古 Ultra 在模子架构上作念出了两个要道编削 —— 深度缩放的 Sandwich-Norm 层归一化和 TinyInit 参数动手化战略。
传统的 Transformer 常常使用 Pre-LN 层归一化,但在深度模子中,Pre-LN 容易导致每个子层输出模范的波动,激勉覆按不褂讪。
盘古 Ultra 使用的 Sandwich-Norm 层归一化,则是在残差联接前对每个子层的输出作念归一化,并凭证网罗深度对动手化值进行缩放,从而有用摒除了覆按过程中的 loss 尖峰,使覆按过程愈加安谧。
用更容易泄露的话说,传统措施仅在每个子层的输入进行归一化,但这种措施针对输出也进行了归一化,造成了 Pre-Norm + 子层 + Post-Norm 的“三明治”结构。
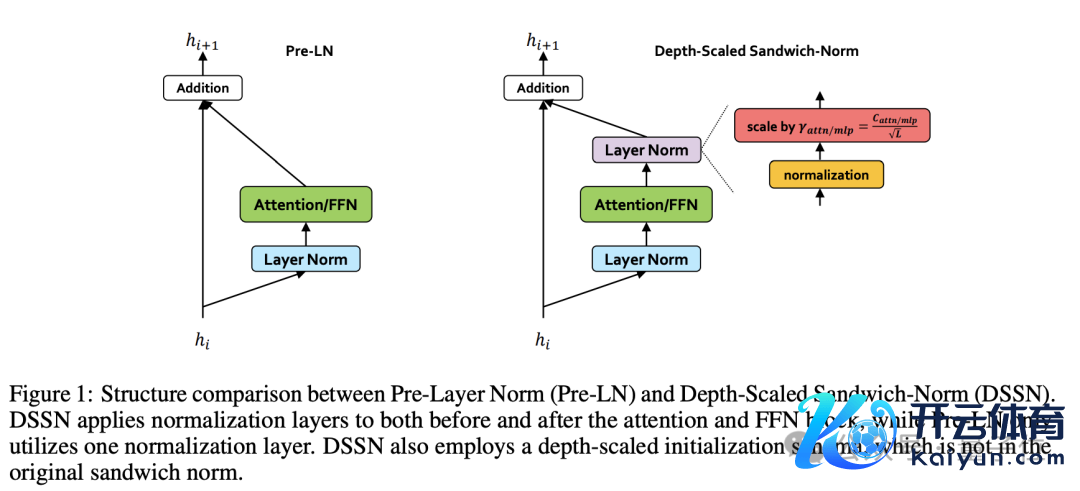
可是,只是使用 Sandwich-Norm 还不及以十足摒除深度模子覆按中的不褂讪性 —— 跟着网罗层数的增多,每一层的输出模范仍然可能出现集合性的漂移。
为此,盘古 Ultra 在 Sandwich-Norm 的基础上,进一步引入了深度缩放机制,对 Post-Norm 中的放缩参数 γ 进行了深度相关的动手化。
至于通盘模子的动手化,传统的动手化常常采纳的 Xavier 动手化措施仅筹商模子宽度,而盘古 Ultra 采纳的 TinyInit 同期依据模子深度和宽度来缩放动手化权重的标准差。
这种动手化方式有助于在前向传播和反向传播过程中,保管各层梯度的方差在一个合理的范围内,幸免了梯度隐匿或爆炸问题,使得覆按过程愈加褂讪,同期也加快了敛迹。
实践标明,TinyInit 在深度模子覆按中得到了更好的敛迹速率和卑劣任务性能;同期针对 embedding 层,保合手权重的标准差接近 1 也能耕种覆按褂讪性。
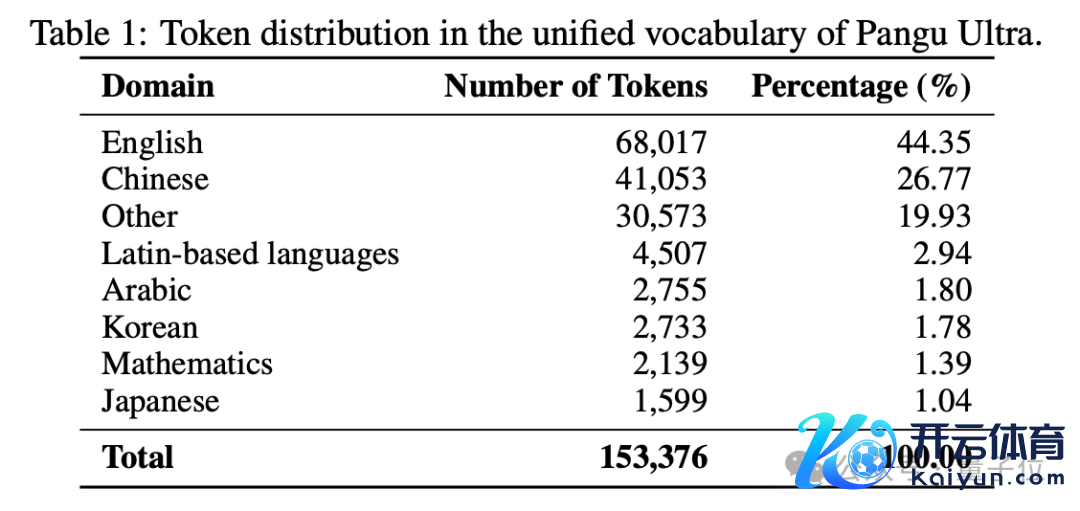
另外,盘古团队也针对 Tokenizer 进行了优化,通过在通用中英文、代码、数学等不同领域诀别进行词频统计,再统一去重,最终得到了一个兼顾领域笼罩和编码服从的 153376 个 token 的均衡词表。
8192 张昇腾 NPU 覆按集群
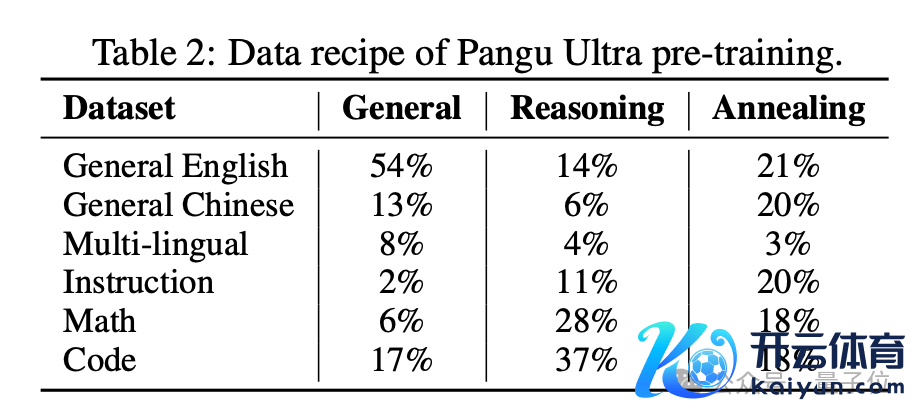
盘古 Ultra 的通盘覆按历程主要分为三个阶段 —— 预覆按、长迤逦文膨胀和教唆调优。
其中预覆按又不错分为三个子阶段:
通用阶段:侧重开辟说话泄露和学问储备,使用了无数中英文通用语料,笼罩网页、竹帛、百科等多个开头;
推理阶段:引入更多高质地的数学和代码数据,以增强模子的推理才略。同期还使用 instruction 数据来匡助模子学习实施任务;
退火阶段:匡助模子巩固学问和推理才略,并强化教唆苦守才略。无数使用问答对和东谈主类响应数据。
询查者们采纳了基于规矩和模子的数据清洗措施,并议论了 curriculum learning 战略,让模子秩序渐进地学习不同难度的样本。
预覆按中使用了 AdamW 优化器,并动态转化超参数。
预覆按后,模子在最长 128K 的长迤逦文数据上进一步覆按,通过扩大 RoPE 的基频来终了长序列建模,以增强处理长文档的才略。
临了的教唆调优阶则段使用监督微调(SFT)和强化学习(RL)来使模子更好地稳健卑劣任务,学会实施教唆并与东谈主类偏好对皆。
覆按措施方面,盘古 Ultra 使用了一个由 8192 个昇腾 AI 处理器构成的大规模计较集群。
集群中每个节点包含 8 个 NPU,通过华为高速缓存一致性互联 HCCS 以全互联的拓扑结构联接,每个 NPU 配备 64GB 内存,节点间则通过 200Gbps 的 RoCE(RDMA over Converged Ethernet)网罗互联。
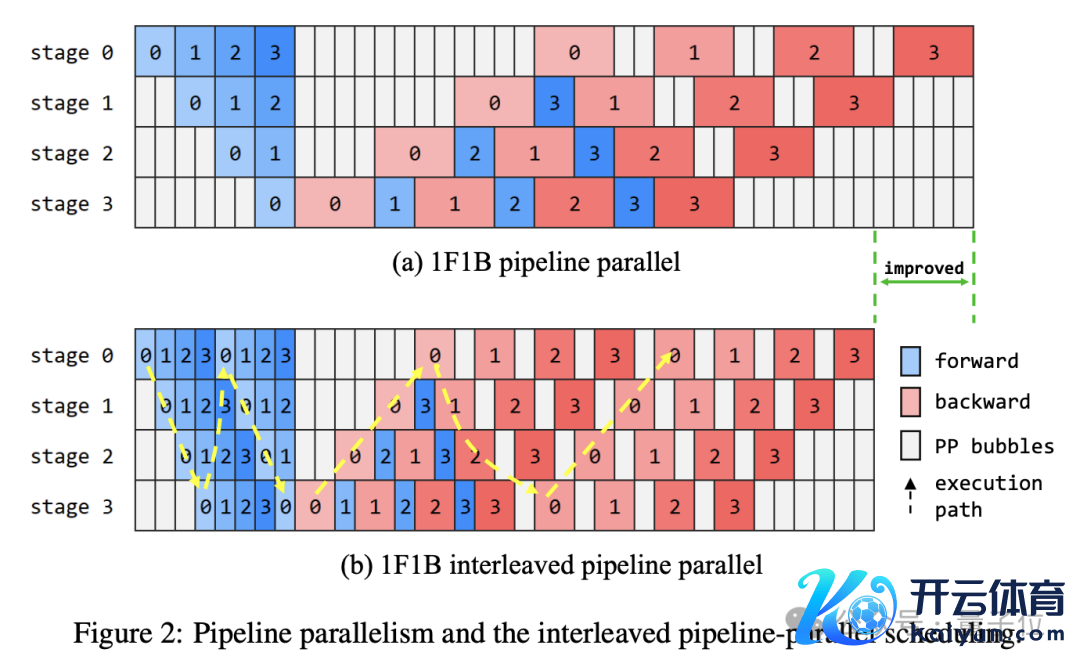
为了终了盘古 Ultra 的高效覆按,询查团队还采纳了一套系统的并行战略和优化技艺。
在并行战略的采取上,盘古 Ultra 概述筹商了模子的规模、数据的特质以及硬件的拓扑,最终采纳了数据并行、张量并行、序列并行和活水线并行等多种并行方式的组合:
128 路数据并行,将覆按数据分片到不同设备,保证了数据蒙胧;
8 路张量并行,哄骗设备里面高带宽切分层内张量,终了高效通讯;
序列并行用于处理超长序列以缩短显存压力;
8 段活水线并行,将不同层溜达到不同设备,造成高效的计较活水线。
在并行战略的基础上,盘古 Ultra 还从多个角度对覆按系统进行了深度优化。
一方面,通过使用 ZeRO(Zero Redundancy Optimizer)溜达式优化器,将模子现象分片到不同设备,大幅缩短了单个设备的内存占用,在提高数据并行度的同期,确保了每个设备的内存包袱在可采纳范围内。
另一方面,询查者们通过多样通讯和计较优化技艺,最小化了通讯支拨,耕种了计较服从:
通过算子和会(Kernel Fusion)将多个小算子统一,减少了内存访谒和 kernel 启动;
通过通讯计较访佛(Communication-Computation Overlapping)终了通讯和计较的深度交汇,装束通讯蔓延;
MC^2(Merged Computation & Communication)和 BOA(Batch Optimization Accelerator)诀别对张量并行和表率化层的通讯进行了有意优化……
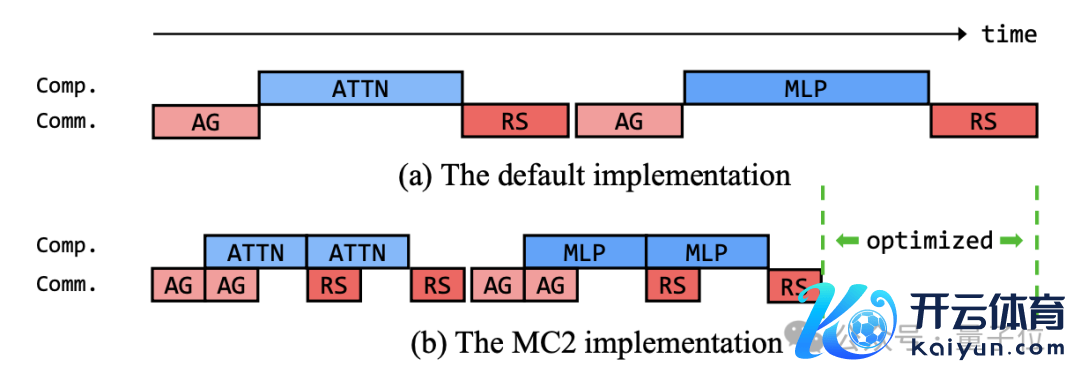
在算法、工程、数据各个层面的密致优化下,盘古 Ultra 终明晰 52% 以上的算力哄骗率。
技艺论述:
https://github.com/pangu-tech/pangu-ultra/blob/main/pangu-ultra-report.pdf
本文来自微信公众号:量子位(ID:QbitAI),作家:克雷西开云体育,原标题《英伟达含量为零!华为密集模子性能并排 DeepSeek-R1,纯昇腾集群覆按》
告白声明:文内含有的对外跳转联结(包括不限于超联结、二维码、口令等形态),用于传递更多信息,无意甄选时间,适度仅供参考,IT之家通盘著作均包含本声明。 ]article_adlist--> 声明:新浪网独家稿件,未经授权阻截转载。 -->